Removing obnoxious colours from Slack with Stylus
I have to use Slack at work, and the obnoxious bright colours it uses for people's names in the “Compact” message view have always annoyed me. Today I finally did something to get rid of them.
I have to use Slack at work, and the obnoxious bright colours it uses for people's names in the “Compact” message view have always annoyed me. Today I finally did something to get rid of them.
What should you do if you
Decathlon's web site has a stupidly-written ToS, and they apparently don't know how to delete a user's account on request.
Lars Svensson's classic “Identification Guide to European Passerines” was first published a few decades ago. It is no longer available from Amazon, but I have been keeping an eye on copies from other sellers on the Amazon marketplace, and I am increasingly puzzled by their proposed prices.
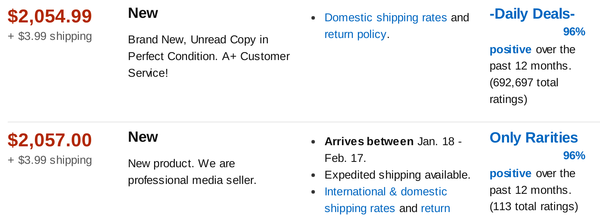
The absurdly high price isn't because the book is new, because there's a used copy for sale at $1847.20. Even the cheapest used copy right now is priced at $458.60, and that's still far more than I can imagine anyone wanting to pay.
The sellers don't look shady at first glance, and many are highly rated over a significant period. Maybe they didn't notice that the book is available elsewhere for twenty-odd euro? But no, it's probably an “algorithm” (note: those are scare quotes) at work.
Every morning, children stream past our house in both directions on their way to school. There are the nearly grown-up, very self-conscious young ladies on the way to the inter-college, dressed in blue and white with neatly plaited and be-ribboned hair. There are groups of brown-and-white children, always squabbling over some snack. There are tiny red-and-blue primary school kids who drift past like tumbleweed—so easily distracted that it's a marvel that they ever make it to school.
And then there are the troublemakers, the wretched blue-and-brown boys who derive entertainment from pinching the valve-caps off our car tyres, or snapping off the occasional windshield wiper. We stuck a webcam in the window overlooking the car to keep an eye on these miscreants. It worked pretty well. A few of the smaller children still write their names on the windows when the car is dusty, but we haven't lost any more valve caps.

But now the webcam has become a local attraction, and we hear children of every colour walking past talking about the “CCTV”, bringing their friends around to point it out, and waving or posing (or dancing!) for the camera. A blue-and-white pair—not yet as serious as their elder sisters–recently made faces at it and ran away horrified but giggling when I replied with a cheerful “Hi”.
Ubiquitous surveillance? What fun!
A month ago,
Sarah Sharp posted
to say
I'm not a Linux kernel developer any more
and
I am no longer a part of the Linux kernel community
.
Academic Journals Online is a predatory publisher with a fraudulent list of editorial board members.
Be wary of offers to translate your pages into other languages—they're often (but not always) low-effort attempts to accumulate inbound links.
Ammu is studying Newton's laws of motion this year in Physics, but she can never remember what the three laws are (partly because they don't seem to be stated clearly in her textbook).
I learned the three laws from a very old-fashioned British textbook that belonged to my great-grandfather—long before I had internet access—so it was a treat to be able to look up Newton's original formulation in the "Philosophiæ naturalis Principia Mathematica" on Gutenberg. After the preface and a series of definitions followed by explanatory notes, the laws of motion are presented in a section entitiled “Axiomata sive Leges Motus” (“Axioms; or, The Laws of Motion”).
ztype is a fun way to practice typing.